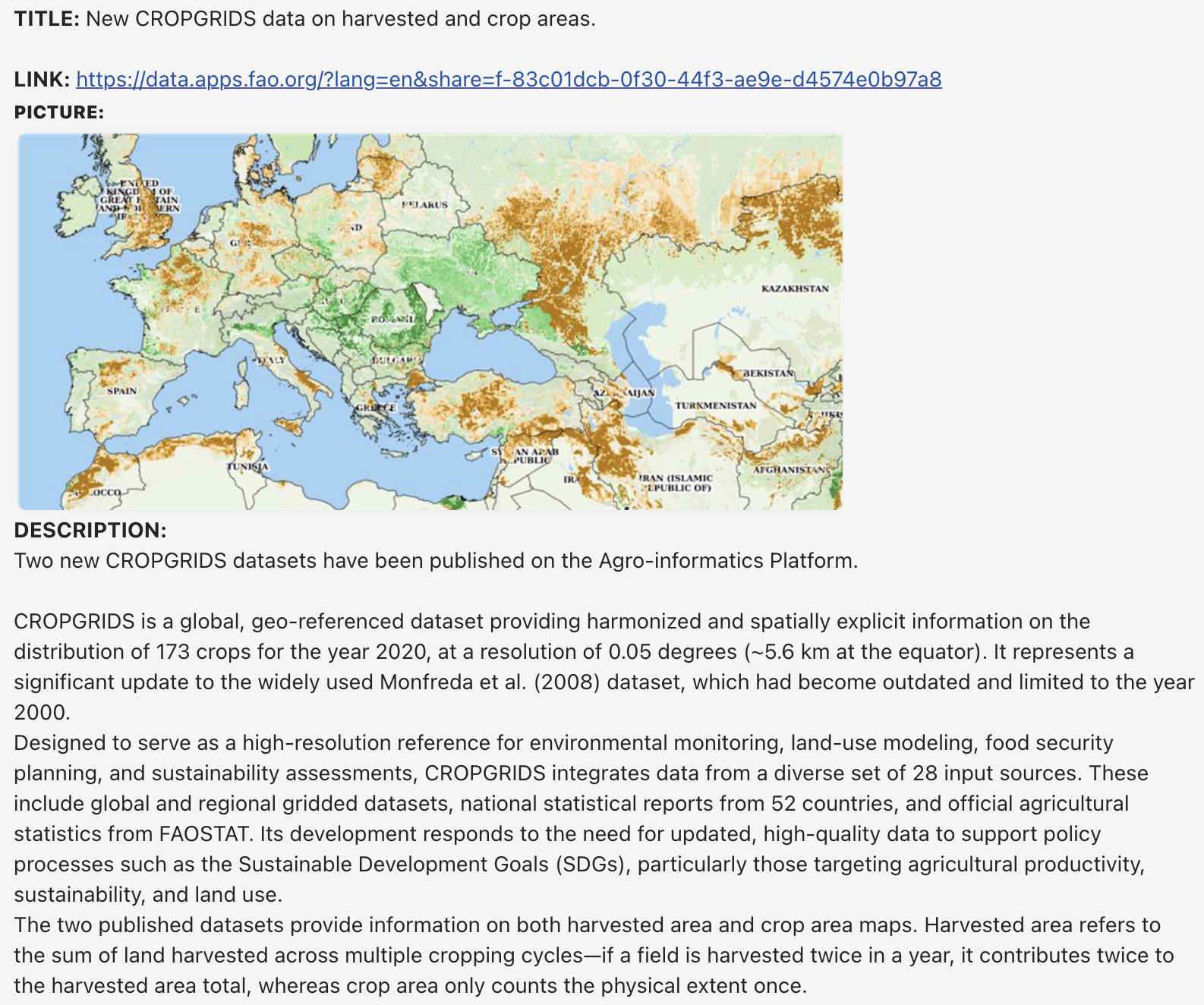
Automating and Enhancing the CROPGRIDS Pipeline: Towards a Fully Integrated, AI-Driven Global Crop Mapping Platform
Conference
10th International Conference on Agricultural Statistics
Format: CPS Abstract - ICAS 2026
Keywords: agriculture and rural development, artificial intelligence, data_fusion, data_pipeline, land-cover-classification
Abstract
Building on the foundational work of Bottini et al. (2025) [1], who demonstrated the operational integration of the CROPGRIDS data fusion protocol into FAO geodata platforms through modular Python implementations, this paper presents the next generation of the CROPGRIDS pipeline: a fully automated, cloud-native system for global crop mapping. The original CROPGRIDS model, as established by Bottini and colleagues, delivered harmonized, high-resolution maps of harvested and planted areas for 173 crops at global scale, with robust methodological transparency, validation, and institutional endorsement. However, the underlying workflow required periodic manual intervention, particularly in the selection and harmonization of new datasets and national statistical office (NSO) updates, thereby limiting the frequency and responsiveness of data refreshes.
In the forthcoming release, the CROPGRIDS pipeline will undergo substantial enhancements to achieve end-to-end automation. The entire pipeline will be migrated to an always-on server environment, with architecture designed for real-time integration and processing. Newly available geospatial datasets, as well as NSO-reported crop statistics, will be ingested and processed automatically, triggering dynamic updates to the published global outputs without requiring manual launches or intervention. This shift addresses previous bottlenecks by ensuring continuous synchronization with the latest available information and supporting near-instant dissemination of the most current spatial crop data.
A game-changer of this automation is the introduction of a custom large language model (LLM) as the system’s data intake gatekeeper. Periodically, the LLM will scan scientific repositories, institutional databases, and open geodata portals, autonomously identifying candidate datasets relevant to global crop mapping. These datasets will then undergo objective benchmarking and quality testing—mirroring the multi-criteria ranking approach of Tang et al. [2]—but with human oversight replaced by transparent, reproducible logic embedded within the LLM framework. Only those datasets passing stringent quality controls and benchmarks will be accepted for pipeline integration, ensuring the evolving CROPGRIDS database remains trustworthy and authoritative.
By combining this LLM-driven discovery mechanism with a fully containerized, API-accessible processing architecture, the new CROPGRIDS platform represents a leap towards the vision of continuously updated, globally harmonized and scalable crop data infrastructure. The anticipated impact is twofold: FAO and its partners will benefit from always-current, interoperable crop maps for policy analysis, food security planning, and sustainable land management; meanwhile, the technical blueprint sets a precedent for the next era of data fusion in agricultural geoinformatics, leveraging AI for both data mining and workflow orchestration. This work thus operationalizes an adaptive, learning pipeline as the backbone of future agricultural monitoring at FAO, aligning with global mandates of FAO for open science, reproducibility, and rapid response to emerging data.
Figures/Tables
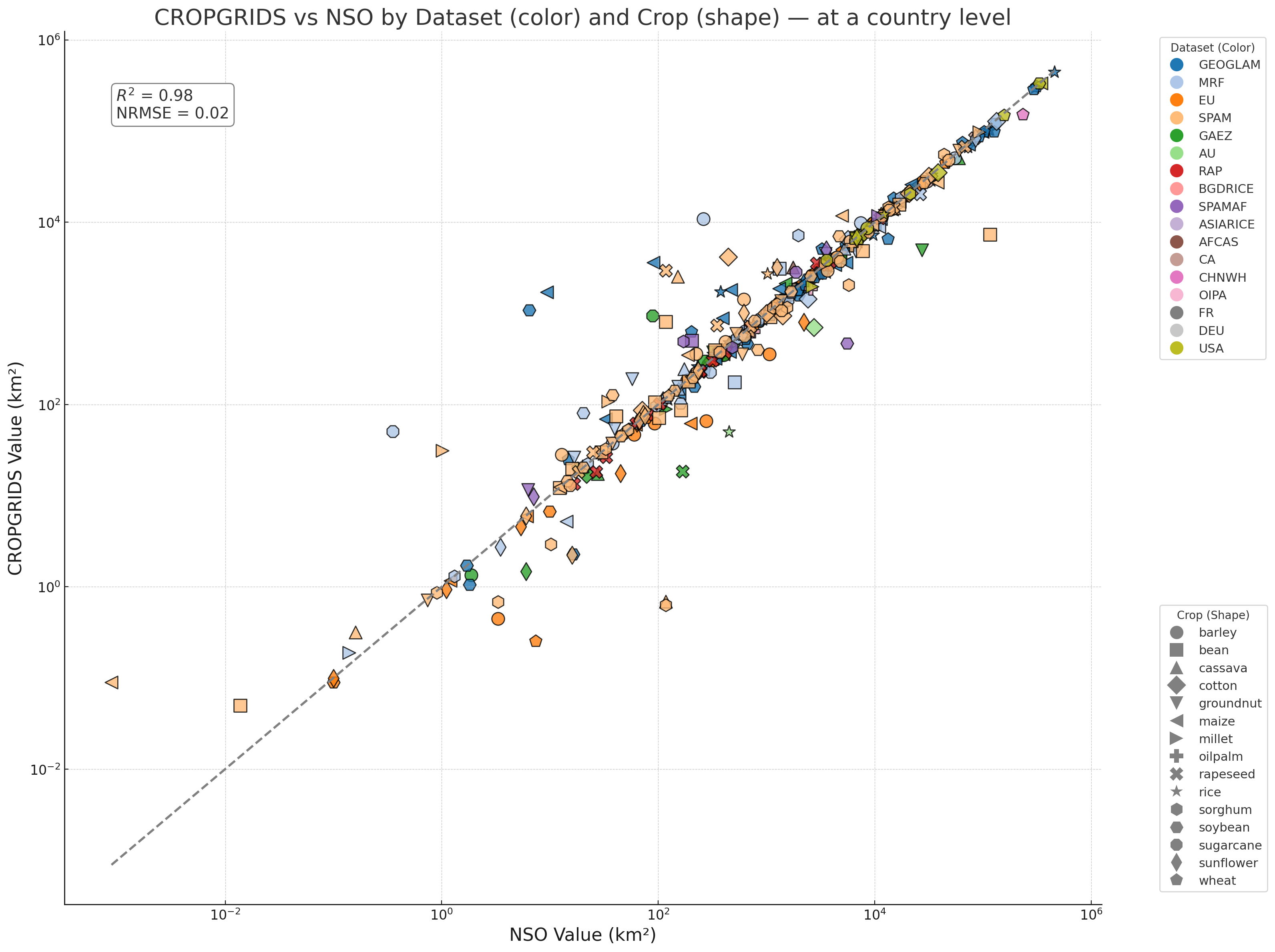
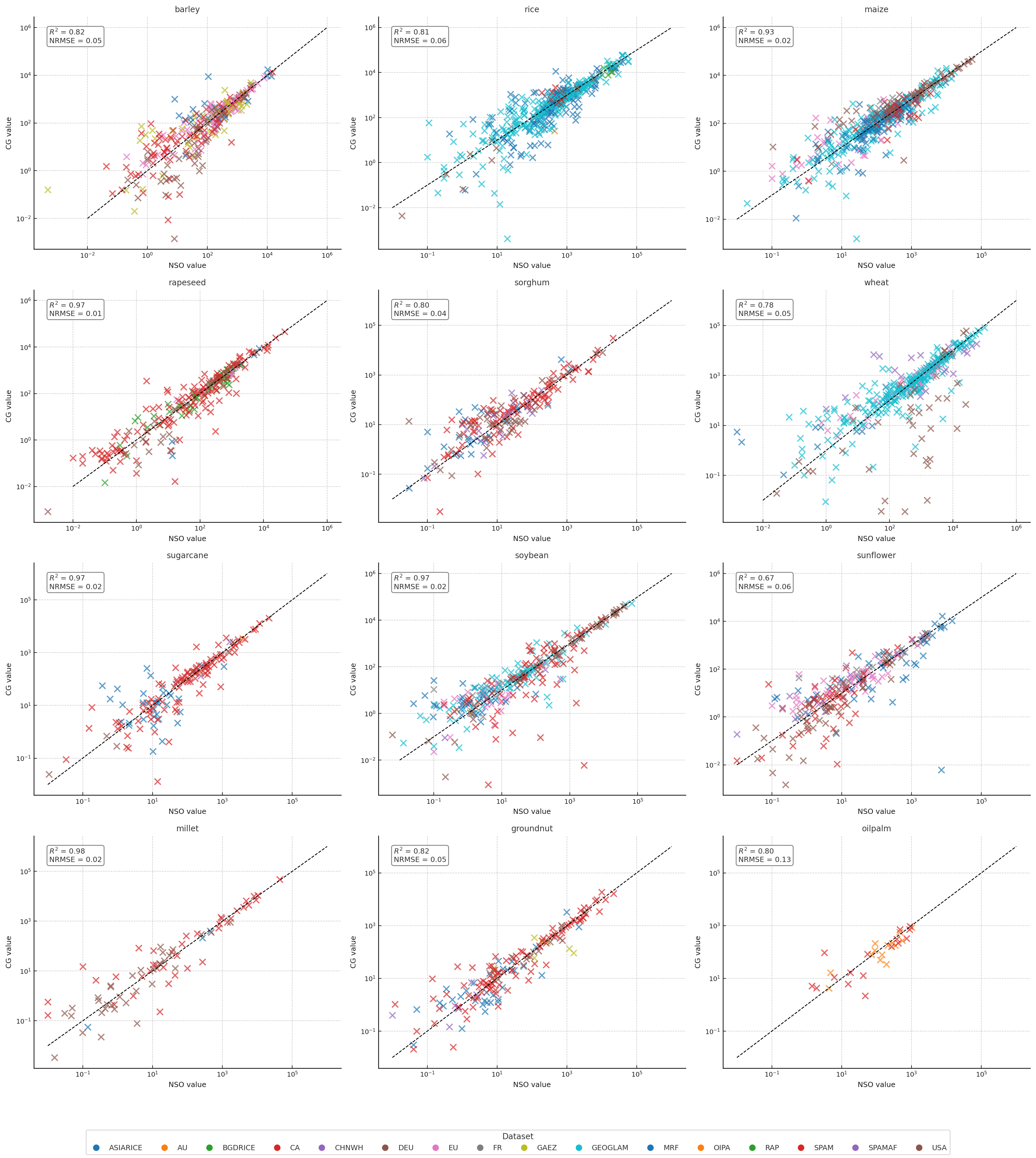
CROPGRIDS vs NSO — at a country level
level1_only
fao website