Advancing Crop Yield estimation through Geospatial Analytics and Machine Learning Techniques
Conference
10th International Conference on Agricultural Statistics
Format: CPS Paper - ICAS 2026
Keywords: #vegetationindexes, crop yield, crop-cutting, geospatial, machine learning
Abstract
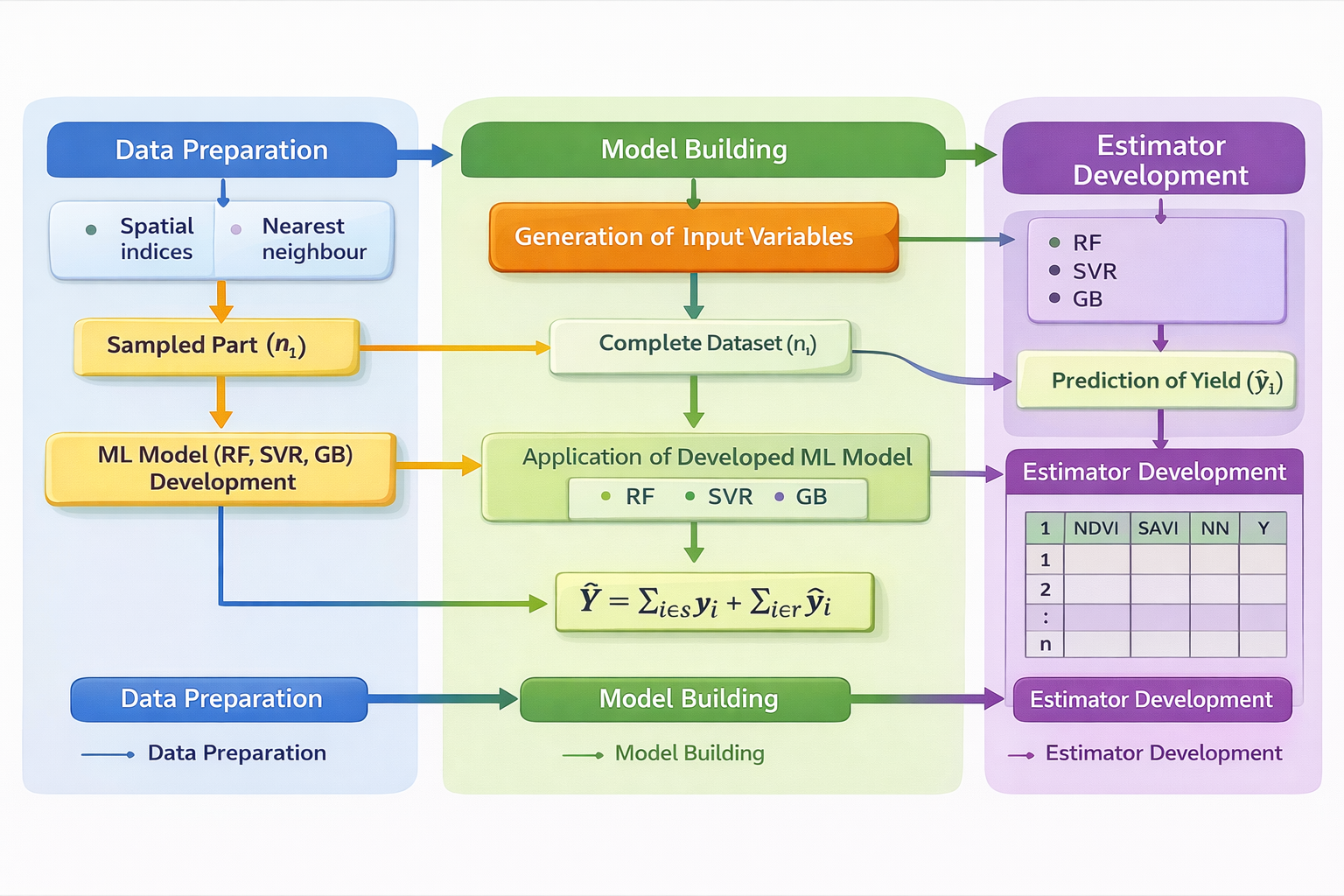
India contributes 7.68% to global agricultural output, with agriculture accounting for a much higher share of the national economy than the global average of 17–18%. Reliable crop yield data is critical for agricultural planning, food security, policy formulation, and resource allocation. In India, the area under cultivation is estimated through complete enumeration, while yields are obtained via sample surveys under the General Crop Estimation Surveys (GCES). These surveys rely on Crop Cutting Experiments (CCEs) conducted annually for major crops using random sampling. Traditionally, 8.5 lakh CCEs are conducted each year, but this number increased to over one crore with the launch of the Pradhan Mantri Fasal Bima Yojana (PMFBY), a yield-based insurance scheme. Although CCEs provide robust field-level data, their scale poses serious logistical and financial challenges. Crop yield is typically spatial in nature and this spatial information can be exploited in order to obtain more precise estimates of crop yield. Recently, the combination of geospatial techniques and machine learning techniques has opened a new arena by providing more efficient and reliable estimates of crop yield. Machine learning algorithms can analyse large datasets from geospatial data and topographical maps to make more precise and timely predictions. Geospatial techniques, which links data to specific locations on Earth, enhances the accuracy of these predictions. Therefore, by integrating advanced computational machine learning techniques with geospatial techniques, crop yield predictions become more precise, and combining these with CCE survey data further enables us to obtain more reliable, and timely yield estimates with reduced number of CCEs which will also bè more cost effective. Therefore, this study develops a novel methodology that integrates geospatial vegetation indices and ML algorithms for crop yield estimation using survey data. ML models are particularly suited for analyzing heterogeneous datasets like satellite imagery. Linking geospatial indices to field survey data enhances reliability and the integration of these approaches increases the accuracy of estimates while reducing the number of CCEs. The empirical study was conducted in Barabanki district, Uttar Pradesh, India. A comprehensive data framework was created by integrating Sentinel-2 multispectral imagery (13 bands, four scenes from February 8, 2018), district and village boundary vector layers prepared using ArcGIS, and ground-based wheat yield data from CCEs conducted during Rabi season. CCE plots with geo-coordinates were sourced from the project “Integrated Sampling Methodology for Crop Yield Estimation Using Remote Sensing, Field Surveys, and Weather Parameters for Crop Insurance,” funded by Ministry of Agriculture and Farmers Welfare. The methodology consists of three major steps input variable generation, model building, and estimator development. Two sets of predictor variables were created. First, nearest neighbour variables, derived from spatial coordinates of CCE plots, used the yield of geographically closest neighbours. Second, vegetation indices included Normalized Difference Vegetation Index (NDVI), Generalised Normalized Difference Vegetation Index (GNDVI), Normalized Difference Red Edge Index (NDRE), Soil Adjusted Vegetation Index (SAVI), and Modified Soil Adjusted Vegetation Index (MSAVI). These variables, combined with observed yield data, produced a comprehensive dataset for ML model training. Three ML algorithms—Random Forest (RF), Support Vector Regression (SVR), and Gradient Boosting (GB)—were employed. The dataset was partitioned into sampled and non-sampled subsets across different proportions (10:90, 20:80, 30:70, 40:60, 50:50) at the village level. The ML models trained the sampled subsets, which then predicted yields for non-sampled part using all predictor variables. Estimator development was based on Royal’s (1970) model-based approach, where population values were viewed as realizations from a stochastic super-population. The finite population was divided into known (sampled) and unknown (non-sampled) components. The sampled part was estimated using conventional GCES methodology, while the nonsampled portion was predicted by ML models trained on sampled data. Final estimates were obtained by pooling sampled and non-sampled parts. Three model-based estimators were developed—RF, SVR, and GB—and compared with the conventional Horvitz–Thompson (HT) estimator. In this design, tehsils were considered as strata, villages were psu, and plots were ssu, with estimators developed at both district and tehsil levels. Performance evaluation included a simulation study in RStudio using custom-developed R scripts. Root Mean Square Error (RMSE) measured prediction accuracy, showing that RMSE declined as sample size increased. GB consistently outperformed RF and SVR across all partitions. Estimator performance was assessed using percentage relative bias (%RB) and percentage relative root mean square error (%RRMSE). All proposed estimators showed very low %RB, indicating negligible bias, while %RRMSE values were consistently lower than those of the HT estimator. Improvements were marked at higher sample sizes, with the GB-based estimator demonstrating the greatest efficiency. The proposed framework improves accuracy and offers the possibility of reducing number of CCEs under PMFBY. In conclusion, this study establishes a robust framework for combining geospatial and ML techniques for more reliable and timely crop yield estimation. This approach can transform agricultural statistics in India, supporting efficient crop insurance, and sustainable food security strategies.
Figures/Tables
Fig 2 Methodology for crop yield estimation